

Table of Contents
What is Real-Time Data Streaming? (Databricks)
It is a process in which data processing takes place quickly in big volumes so the firm that is trying to extract the information from that data can respond in real-time to the changing conditions. Big volumes of data are stream processed so that the organizations are able to respond to fraud activities and any potential threats. The process is also used to boost the business benefits.
The major applications of real-time data streaming are:
- Fraud Detection
- Risk Management
- E-Commerce
- Pricing and Analytics
- Network Monitoring
Structured Streaming:
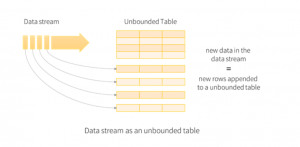
The data which comes from data streaming is taken as an unbounded input table. A new row is added to this unbounded input table for each new data in the data stream. The entire input isn’t stored but the final result is equivalent to the entire input.
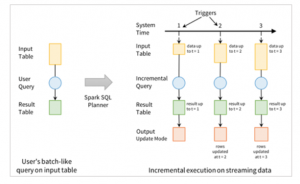
We use an input table to define a query which gives us a final result table written to an output sink. This batch-like query is converted into a streaming execution plan by Spark and the process is known as incremental execution.
In this process, the state required to update the final result every time a query comes in is calculated by Spark. For each incoming query, Spark looks for new data within the input table and the results get updated on an incremental basis.
The end results in the result table are generated by the queries on the input table. The trigger interval is of three seconds and for all trigger intervals new rows through incremental execution are added to the input table and which updates the result table. Each time this happens the results are written as an output. Whatever gets written in the external storage is defined by the output.
Spark Structured Streaming on Databricks:
The standard data set can also be used to express streaming additions, stream-to-batch joins in Python, R, Java, etc. The computations are done through an optimized Spark SQL Engine. The end-to-end connotation delivery is also ensured by structured streaming. The delivery of fault tolerance is by means of a checkpointing and a write-ahead logging process.
For a strong streaming application, a robust failure is also required. For a query, if we enable checkpointing, the query can be restarted after a failure and the restarted query will continue at the exact point where the failed one left off, but during the process, it also ensures guaranteed data consistency and fault tolerance.
For a long time in databases, write-ahead logs have also been used to ensure the durability of data operations that are carried on. First, in a durable log, the intention of the operation is written down and then that operation is applied to the data. If b chance any difficulty arises during the operation or the system fails, it can reapply the operations by reading the log.
Also when write-ahead logs are enabled, all the data that is received is saved to log files in a fault-tolerant file system. This makes the data that is received durable across any failure in Spark Streaming. If we use checkpointing, the stated directory will be used for both write-ahead logs as well as checkpointing.
Sending Data to Azure Event Hubs:
It is a real-time data ingestion service that can respond to business challenges by streaming millions of events per second from any source to build dynamic pipelines. You need to follow these steps in order to send events to and receive events from Azure Event Hubs :
- Create a console application
- Add the Event Hubs NuGet package
- Write code to send events to the event hub
- Receive events
- Create an Azure Storage and a blob container
- Create a project for the receiver
- Add the Event Hubs NuGet package
- Update the Main method
Real-Time Storage using Delta Lake Tables:
Databricks is an analytics platform that combines the benefits of both Data Lake and Data Warehouse by providing a Lake House Architecture. To operate on a multi-cloud lakehouse architecture which will provide a robust data warehouse performance at data lake economics.
Databricks SQL Analytics enables analysts and data scientists to accurately carry out SQL queries on the freshest and most complete data using their tools of choice — directly on your data lake while simplifying architectures by decreasing the need for more contrasting systems.
If we are storing data to delta tables instead of external storage the complexity of the process is reduced. In Delta, we have the feature to use ACID transactions to update the table for quicker data ingestion. It also has some advanced features and offers more flexibility in changing the content.
An ordered record of a transaction is called a DeltaLog. Once the transaction is completed, the files are added to the transaction log
Some of the major features offered by Delta Lake Tables are:
- Automate Data Pipeline
- Automatic Testing
- Automatic Error-Handling
Visualization using Power BI:
We can visualize a streaming dataset in Power BI by adding a tile and using the dataset that is streaming as a custom streaming data source. These streaming tiles that are based on the streaming dataset are customized for quick display of real-time data. The latency between when data is entered into Power BI and when the visual is updated is very little.
Conclusion:
Structured Streaming in Apache Spark is the best framework for writing your streaming ETL pipelines, and Databricks makes it easy to run them in production at scale. Using a combination of cloud-based services with Azure Databricks and Spark Structured Streaming with the visualization features of Power BI and using real-time storage on data lake tables you will be able to experience a robust, fault-tolerant, near-real-time experience.
Visit for more best articles



